5秒だけでもいいーーー
すいません、5秒もありません。1秒だったかしら。音が出ますのでご注意を。
話というより声ですね。
まあ、正確に言えば「俺の声」ではないわけですが。
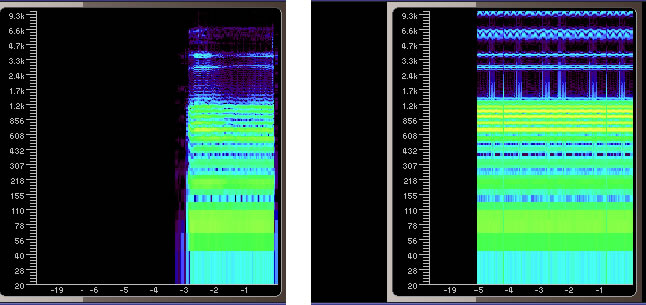
俺の声「あ」をFFT掛けて、それとフォルマント的発想を加味して正弦波で再構成したものがこれです。できるだけ簡単化するために詳細は無視してますけど。いやかなり大雑把。の割には俺の声と似ている気がしてます。ちなみに絵は・・一目瞭然ですが左が実際の声、右が合成音声です。
ただちょっと音が硬いかな?気持ち奇数倍音落としたほうがいいかしら、とか思ってます。
とりあえずここまでやるのにいろいろと音声関係のページを見ましたけど、結構役に立たないもんです。
一般的に音声解析で使うフォルマントは2つか3つみたいです。見た限りすべてのページでそうなってます。
でも、これは機械で認識する上での手段としての話であって、音声合成目的だと足りない気がしました。それだけだと僕の耳ではかなり認識しづらいんです。
「あ」の音は700Hzあたりと1k~1.2kあたりにフォルマントがある資料がほとんどで、モノによってあとは3kあたりにもあったりしますが、これだけだとちょっと「あ」とは聞きづらいんですよ、僕。
これに3.7k、6k、9.6k(9.6はなくても認識はできるけど、ないと今一すっきりしないので;)も足してやったらちゃんと「あ」に聞こえました。
たぶん人間はそこまで単純な周波数分けで音聞いてないと思いましたよ、たいていの研究ほどは。
まあそんなに複雑なことしてないんですけど。僕も。
とはいえ一応フォルマントをきちんと意識して作ってるので、ちゃんと音階変えても「あ」に聞こえますよw
・・聞こえるか聞こえないかというレベルの話まあ当然で、声の個性の意味からしても高次倍音特性は必要なので、今やらなくても後でやるところだったんですけどね;;;
データの調整は必要として、さし当たって問題と言えるのはフォルマントの形ですか。現在つりがね型(いわゆる標準偏差の曲線w)関数でやってますけど、実波形は左右不均衡にみえます。もしかするとフォルマント自体はこれで良いものの、共振波形に対しても倍音があるがゆえ右側が左側より大きい形になっている可能性もあります。ちょっとそのあたりは研究が足りてませんね。ま、いろいろ調べてみましょう。
・・てかこの声紋見る限り、俺の声9.6k見えるほど出てないな;;そして6kは強すぎですな;
フォルマント全体に強すぎかな。「あ」に聞こえないのが怖いという一番陥りやすいパターンですな、これ。別に歌だったらきちんと聞こえない可能性たかいくらいなのにw
まあこれから調整です。